

Python PDF轉DOCX全攻略:批次轉換腳本、套件庫與高效工具推薦

摘要
本文深入探討 python pdf轉docx 的各種轉換方法,涵蓋 pdf2docx 與 PyMuPDF 等 Python 套件庫,以及專屬的桌面端工具。文章重點介紹了批次處理腳本、OCR 光學字元辨識功能,以及自動監控資料夾的解決方案,助您打造穩定可靠的檔案處理工作流程。


| 問題類型 | 常見原因 | 預先檢查 / 診斷 |
|---|---|---|
掃描版 PDF | 無可選取文字 | 開啟 PDF 並嘗試反白文字;若無法反白,則需要 OCR |
複雜表格/版面 | pdf2docx 沒有版面引擎 | 先轉換一頁並檢查欄位是否位移 |
內嵌字型 / 亂碼 | 字型子集化或非標準編碼 | 掃描 DOCX 中是否有 □ 或隨機符號 |
大批次處理崩潰 | 記憶體或相依性衝突 | 使用 5–10 個檔案進行測試;隨時注意 RAM 使用量 |

| 方法 | 最適合 | 主要限制 |
|---|---|---|
pdf2docx | 數位 PDF 的快速轉換 | 處理複雜版面能力弱;無 OCR |
PyMuPDF + python-docx | 完全掌控與自訂提取邏輯 | 需要大量編碼來重建版面 |
pdfplumber | 以表格為主的 PDF | 無 DOCX 匯出;僅限文字提取 |
Pandoc | 可編寫腳本的管道;多格式工作流程 | PDF→DOCX 的品質取決於 LaTeX/PDF 閱讀器 |
LibreOffice CLI | 批次自動化;無頭轉換 | 版面保真度不一;無 OCR |
| 功能 | 支援度 |
|---|---|
直接 PDF→DOCX | 是 |
OCR | 否 |
內嵌字型 | 部分 |
複雜版面 | 中等 |
自動化 | 是 |
XFA 表單 | 否 |
| 功能 | 支援度 |
|---|---|
直接 PDF→DOCX | 否(需手動編碼) |
OCR | 否(需要外部 OCR) |
內嵌字型 | 唯讀 |
複雜版面 | 高度控制,手動 |
自動化 | 極佳 |
XFA 表單 | 否 |
| 功能 | 支援度 |
|---|---|
直接 PDF→DOCX | 否 |
OCR | 否 |
內嵌字型 | 否 |
複雜版面 | 適合表格 |
自動化 | 是 |
XFA 表單 | 否 |
| 功能 | 支援度 |
|---|---|
直接 PDF→DOCX | 是(透過 LaTeX) |
OCR | 否 |
內嵌字型 | 否 |
複雜版面 | 有限 |
自動化 | 極佳 |
XFA 表單 | 否 |
| 功能 | 支援度 |
|---|---|
直接 PDF→DOCX | 是 |
OCR | 否 |
內嵌字型 | 部分 |
複雜版面 | 中等 |
自動化 | 極佳 |
XFA 表單 | 否 |

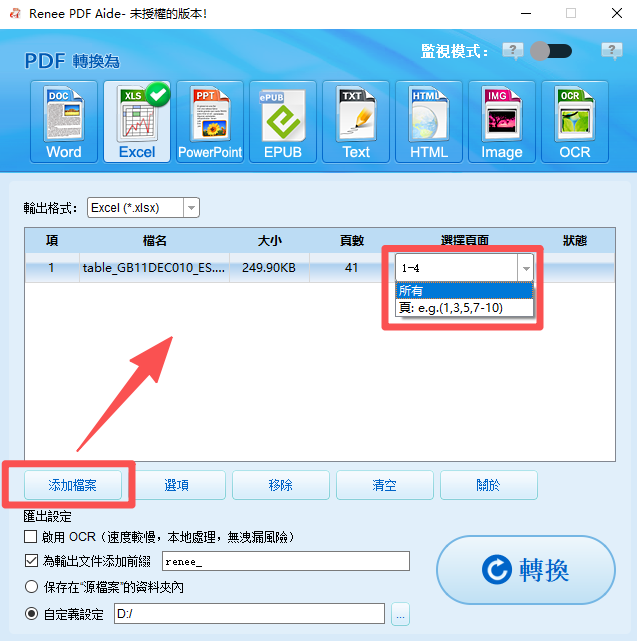
轉換為 Word/Excel/PPT/Text/Image/Html/Epub
多種編輯功能 加密/解密/分割/合併/浮水印等。
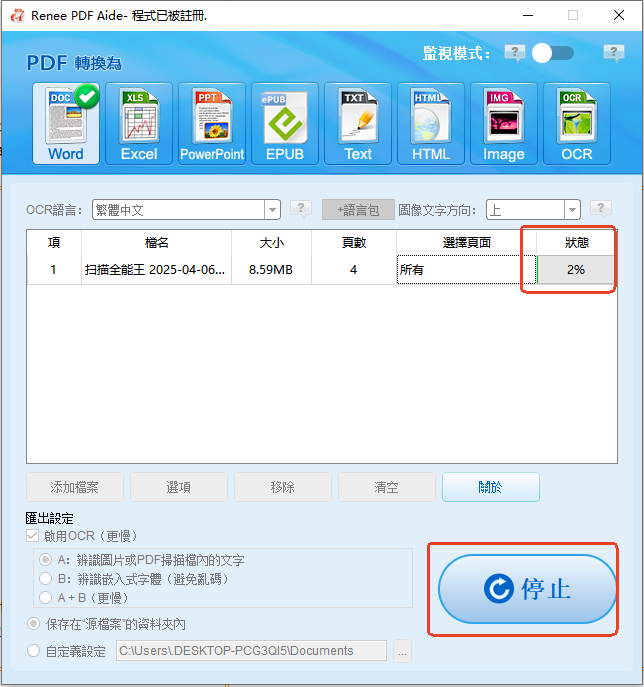
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
編輯/轉換速度快 可同時快速編輯/轉換多個檔案。
支援 Windows 11/10/8/8.1/Vista/7/XP/2K
轉換為 Word/Excel/PPT/Text/Image/...
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
支援 Windows 11/10/8/8.1/Vista/7...
主要優勢包含

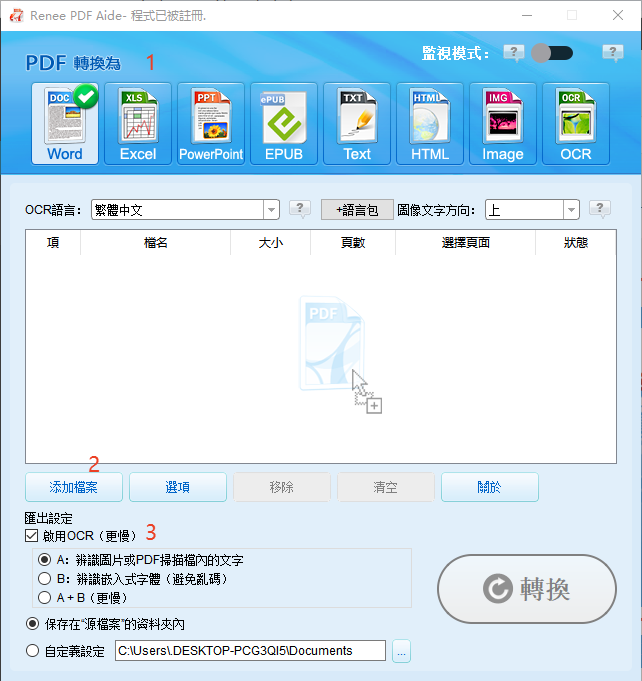
轉換為 Word/Excel/PPT/Text/Image/Html/Epub
多種編輯功能 加密/解密/分割/合併/浮水印等。
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
編輯/轉換速度快 可同時快速編輯/轉換多個檔案。
支援 Windows 11/10/8/8.1/Vista/7/XP/2K
轉換為 Word/Excel/PPT/Text/Image/...
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
支援 Windows 11/10/8/8.1/Vista/7...
操作步驟
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
限制與不足
- 完全的程式碼掌控與客製化
- 免費用於簡單的原生 PDF
- 輕鬆整合至現有的 Python 管道
缺點:
- 掃描檔案無內建 OCR
- 複雜表格與圖片經常未對齊
- 需要外部工具進行排程執行
- 不同 PDF 版面需要大量除錯
| 使用情境 | 推薦工具 |
|---|---|
對 1–2 個簡單 PDF 進行快速測試 | Python pdf2docx 腳本 |
掃描版 PDF 或複雜版面 | 具備 OCR 的 Renee PDF Aide |
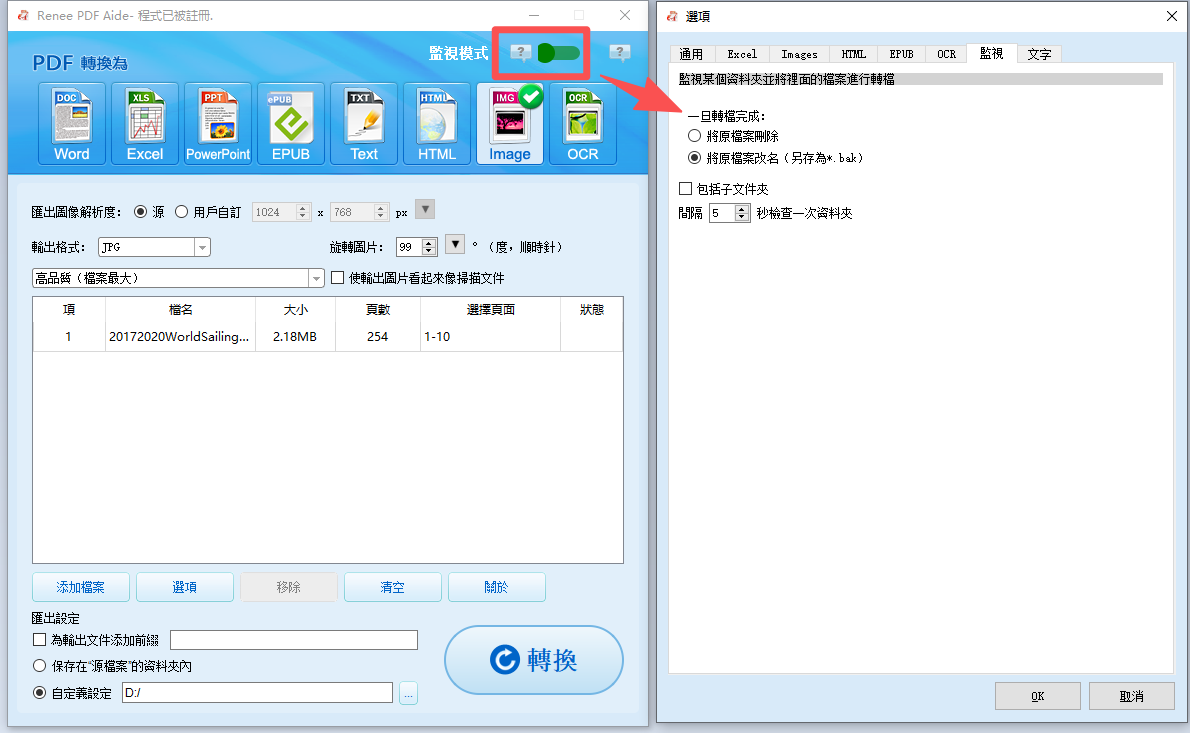
批次轉換(50 個以上檔案) | Renee PDF Aide(批次處理 + 監控樣式) |
排程夜間轉換 | Renee PDF Aide 監控樣式 |
完全掌控程式碼 + 簡單 PDF | PyMuPDF + watchdog 自訂腳本 |
Renee PDF Aide 能處理 Python 腳本無法讀取的掃描版 PDF 嗎?
為什麼 pdf2docx 會遺失我的表格格式或欄位對齊?
Renee PDF Aide 的最大批次處理數量或頁數限制是多少?
我能使用 Python 或 Renee PDF Aide 將密碼保護的 PDF 轉換為 DOCX 嗎?
Renee PDF Aide 支援 XFA 表單(銀行/政府機構 PDF)嗎?

轉換為 Word/Excel/PPT/Text/Image/Html/Epub
多種編輯功能 加密/解密/分割/合併/浮水印等。
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
編輯/轉換速度快 可同時快速編輯/轉換多個檔案。
支援 Windows 11/10/8/8.1/Vista/7/XP/2K
轉換為 Word/Excel/PPT/Text/Image/...
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
支援 Windows 11/10/8/8.1/Vista/7...
相關主題 :
離線 PDF 轉 DOCX 轉換器推薦:安全將 PDF 轉為可編輯 Word 檔案的完整教學

2026-06-03
鐘雅婷 : 本完整指南評測了多種檔案轉換軟體,並重點介紹了專業的「離線 PDF 轉 DOCX 轉換器」...



使用者評論
發表評論