

如何從PDF擷取文字

摘要
想輕鬆從PDF檔案中擷取文字?本指南教你運用免費工具與OCR技術,無論是手動複製還是自動化處理,都能快速搞定!無論你是學生、上班族,還是需要處理掃描收據,這篇「PDF文字擷取」實用指南都能幫你省下大量時間,立即掌握高效技巧!



逐頁複製貼上文字的步驟


複製 PDF 文字出現亂碼
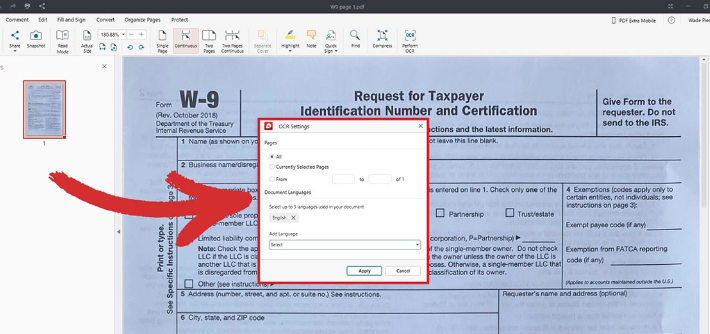
掃描型 PDF 檔案

轉換為 Word/Excel/PPT/Text/Image/Html/Epub
多種編輯功能 加密/解密/分割/合併/浮水印等。
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
編輯/轉換速度快 可同時快速編輯/轉換多個檔案。
支援 Windows 11/10/8/8.1/Vista/7/XP/2K
轉換為 Word/Excel/PPT/Text/Image/...
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
支援 Windows 11/10/8/8.1/Vista/7...
如何使用 AI 擷取文字
Extract all text from this image as a bullet list.
Extract all text from this pdf file.

許多情況下,使用者必須手動逐頁截圖,不僅耗時還容易出錯。若需處理大量檔案或專業用途,專用的桌面軟體仍是更可靠且高效的选择。
📊 PDF 處理工具比較:免費 vs. 付費方案(2025 年更新)
| 平台 | 免費版本 | 付費/進階版本 | PDF 轉換支援 | 匯出格式 | 2025 年 AI-OCR 增強功能 |
|---|---|---|---|---|---|
微軟 Copilot | 可上傳最多 50 頁的 PDF;大型檔案需分割。與 Edge 整合,提供快速 OCR。 | Microsoft 365:無頁數限制,具備 AI 驅動的表格提取功能。 | ❌ 無直接轉換功能,但可透過 API 匯出為 JSON。 | 純文字、JSON | Cognitive Services v3.1:掃描檔案辨識準確率達 98%。 |
ChatGPT(OpenAI) | 無法直接上傳;需貼上文字或截圖。 | Plus/Team:可上傳最多 300 頁;自動 OCR 處理圖片。 | ❌ 僅提供摘要;需透過外掛程式匯出。 | 純文字、項目符號清單 | 整合 LlamaParse:支援多語 PDF(例如英文+印地語)。 |
Grok(xAI) | 可上傳約 50 頁;支援語意搜尋文字。 | Premium:約 200 頁,支援批次處理。 | ❌ 僅支援純文字。 | 純文字 | 強化 OCR 功能,可處理低品質掃描檔;注重隱私保護。 |
什麼是 Renee PDF Aide?
轉換為 Word/Excel/PPT/Text/Image/Html/Epub
多種編輯功能 加密/解密/分割/合併/浮水印等。
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
編輯/轉換速度快 可同時快速編輯/轉換多個檔案。
支援 Windows 11/10/8/8.1/Vista/7/XP/2K
轉換為 Word/Excel/PPT/Text/Image/...
OCR 支援從掃描的 PDF、圖像和嵌入字體中提取文本
支援 Windows 11/10/8/8.1/Vista/7...
擷取文字至 Word

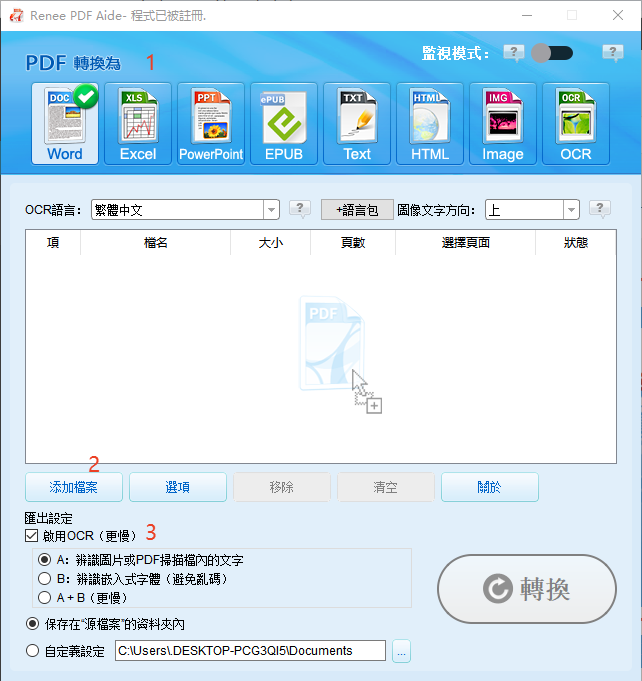
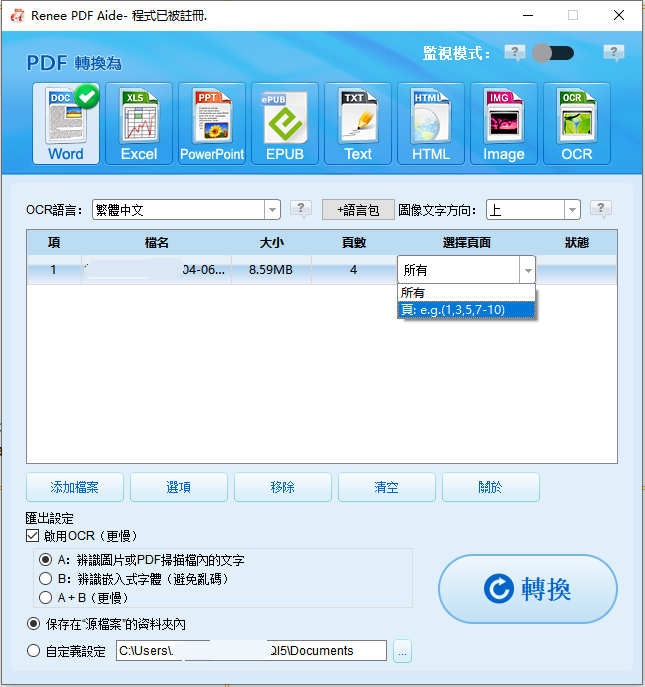
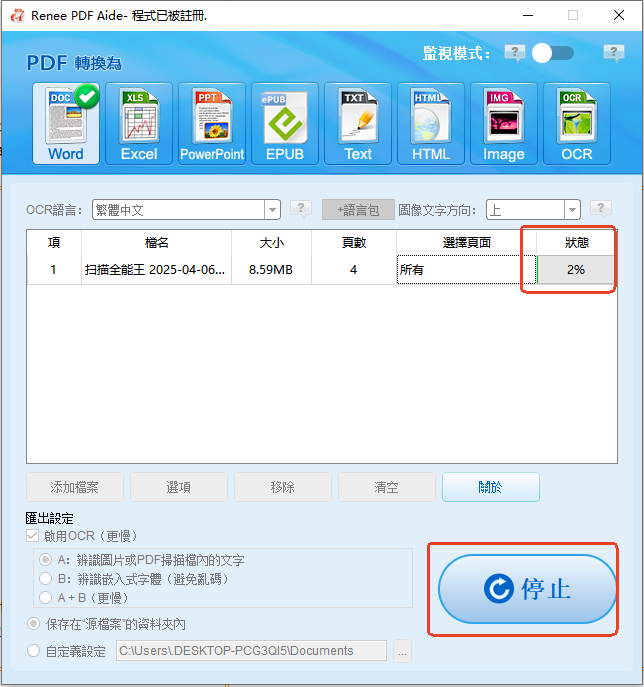
擷取文字至 Excel
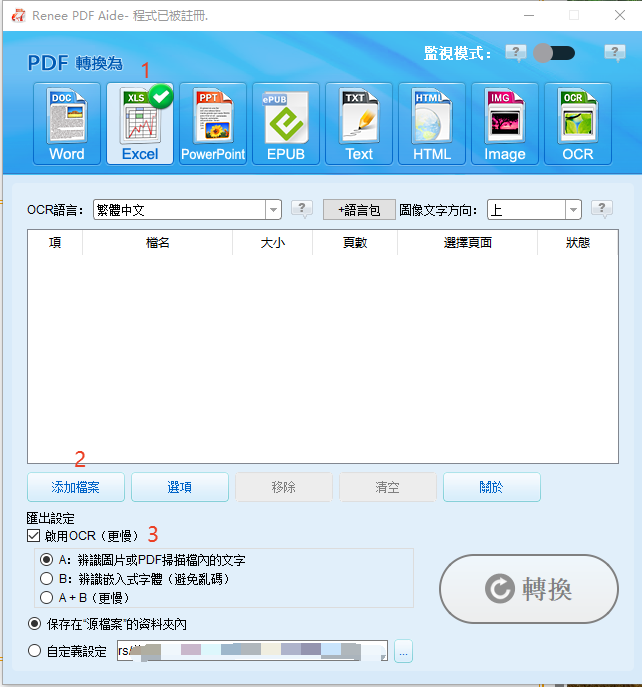
擷取文字至 PowerPoint
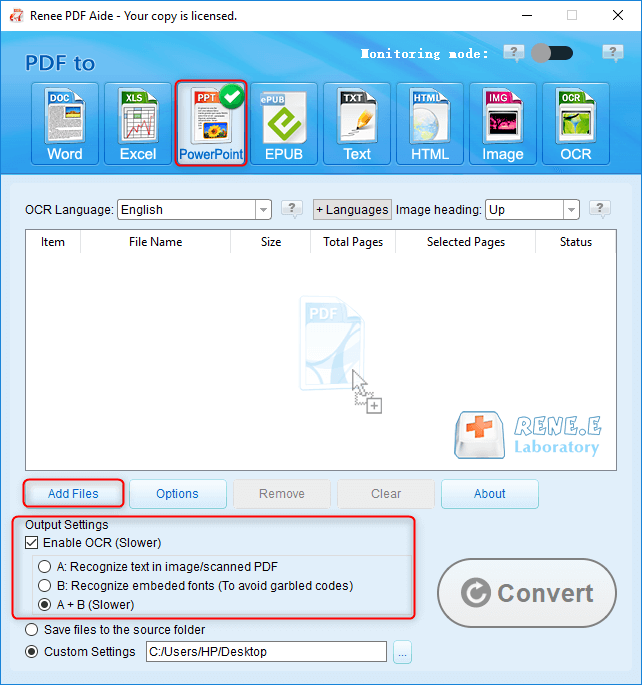
擷取文字至 TXT
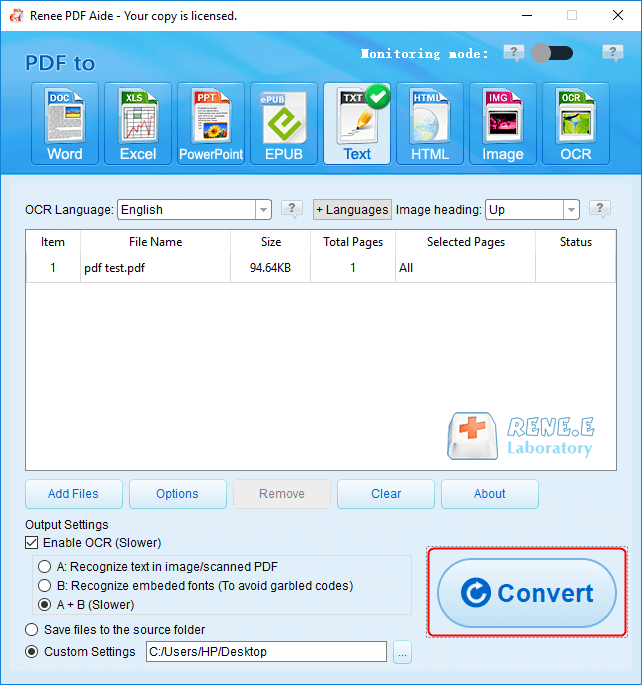

| 工具 | 功能 | 限制 |
|---|---|---|
PDF Candy | 免費 PDF 轉 TXT,掃描檔自動 OCR,介面友善。適合從型錄中提取商品清單。 | 檔案大小限制(約 100MB),免費版有廣告,尖峰時段處理較慢,上傳至伺服器有隱私風險。 |
PDF2Go | 無需註冊,支援行動裝置,OCR 快速轉 TXT。適合從會議 PDF 中快速擷取筆記。 | 檔案大小有限制,可能有資料外洩風險,偶爾會遺失格式,需使用網路連線。 |
Python 腳本範例
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path, output_format="txt", lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = []
for page_num, page in enumerate(doc, start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- 第 {page_num} 頁 ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
ocr_text = pytesseract.image_to_string(img, lang=lang)
text_output.append(f"--- 第 {page_num} 頁 (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)[0]}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file, "w", encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("不支援的匯出格式。請使用 'txt' 或 'docx'。")
return output_file
except Exception as e:
print(f"處理 PDF 時發生錯誤:{e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file, output_format="txt", lang="eng+hin")
if result:
print(f"文字已擷取至:{result}")✅ 優點:免費、可自訂
❌ 缺點:需設定環境
hin+eng以提升 OCR 準確度。可儲存為 TXT 以取得純文字,或儲存為 Word 以保留格式進行編輯。| 使用者類型 | 最佳方法 | 優點 | 下一步行動 |
|---|---|---|---|
新手 | 複製貼上或線上工具 | 簡單易用,無需花費或技術門檻。 | 今天就用 Foxit Reader 開啟你的 PDF 吧! |
專業人士 | Renee PDF Aide | 快速轉換為 Word/Excel,離線處理更安全。 | 從官方網站下載試用版。 |
技術熟練者 | Python 搭配 OCR | 自動化處理,適合大數據量。 | 安裝相依套件並測試程式碼。 |
行動裝置使用者 | AI 助手 | 只要有網路,隨時隨地都能使用。 | 試用 ChatGPT Plus 以支援檔案上傳。 |
如果擷取的文字出現亂碼或不完整怎麼辦?
線上工具處理機密 PDF 安全嗎?
可以從加密 PDF 中擷取文字嗎?
如何處理大型 PDF(例如 500 頁以上)?
如何從多語 PDF 中擷取文字?
hin+eng),以準確擷取雙語 PDF 內容。


使用者評論
發表評論